LLMOとは?SEOとの違いとAI検索(AIO/SGE)対策の具体的手順

LLMOとは、ChatGPTやGoogleのAI Overviews(旧SGE)などのAIモデルに、自社情報を正確に参照・回答させるための最適化手法です。従来のSEOとは異なり「順位」ではなく「引用」を狙います。
- 「AI検索(AIO)の登場でSEOが終わると聞いて不安」
- 「自社ブランドがAIに正しく認識されていない」
- 「具体的に何をすればいいかわからない」
このような悩みを抱えるマーケターや経営者に向けて、この記事ではLLMOの定義とSEOとの違い、今日から実践できる技術的な対策(構造化データ等)、Next.jsを用いた実装例までを、実務専門家の視点で解説します。
LLMO(大規模言語モデル最適化)の定義とSEOとの違い
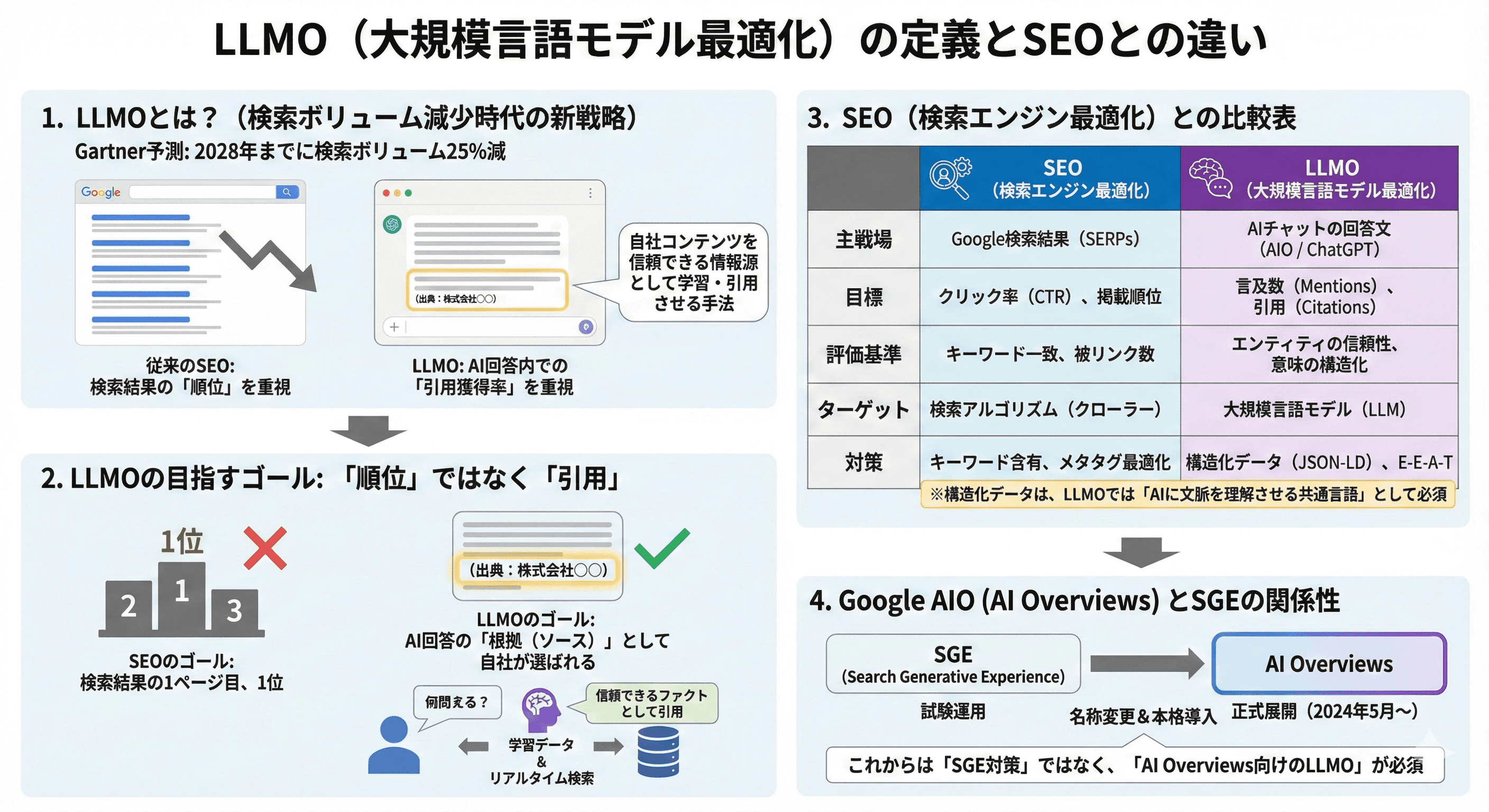
LLMO(Large Language Model Optimization)は、GoogleのAI OverviewsやChatGPTなどのLLMに対し、自社コンテンツを信頼できる情報源として学習・引用させる手法です。
従来のSEOが検索結果の「掲載順位」を指標とするのに対し、LLMOはAI回答内での「引用獲得率」を重視します。
米国のリサーチ&アドバイザリー企業Gartnerは2028年までに検索ボリュームが25%減少すると予測しており、検索流入に依存しない参照元の確立が急務です。
参考:GartnerのAIエキスパート、Nicole Greene氏、AIによる検索体験の未来を見据える
LLMOが目指すゴールは「順位」ではなく「引用」
従来のSEOにおいて、私たちは「検索結果の1ページ目、できれば1位」を目指してきました。しかし、LLMOにおいてその指標は通用しません。
目指すべきは、AIが生成する回答文の中に「根拠(ソース)」として自社名やURLが組み込まれることです。
ユーザーがAIに対して質問を投げかけた際、AIは膨大な学習データやリアルタイム検索結果から答えを合成します。
この合成プロセスにおいて、自社の情報が「信頼に足るファクト」として選ばれるかどうかが勝負の分かれ目となります。
SEO(検索エンジン最適化)との比較表
SEOとLLMOは対立するものではなく、補完関係にありますが、重視するポイントは明確に異なります。以下の表で整理します。
SEO(検索エンジン最適化)
主戦場
Google検索結果のリスト(SERPs)
目標
クリック率(CTR)と掲載順位
評価基準
キーワードの一致、被リンク数
ターゲット
検索アルゴリズム(クローラー)
対策
キーワード含有、メタタグ最適化
LLMO(大規模言語モデル最適化)
主戦場
AIチャットの回答文(AIO / ChatGPT)
目標
言及数(Mentions)と引用(Citations)
評価基準
エンティティの信頼性、意味の構造化
ターゲット
大規模言語モデル(LLM)
対策
構造化データ(JSON-LD)、E-E-A-T
Web集客の全体像:SEO・広告・SNSとLLMOの組み合わせ戦略に関して知りたい方はこちら
特に重要なのは「構造化データ」の扱いです。
SEOではリッチリザルト表示のために使われますが、LLMOでは「AIに文脈を理解させるための共通言語」として必須となります。
Google AIO(AI Overviews)とSGEの関係性
SGE(Search Generative Experience)は、Googleが試験運用していたAI検索機能の名称です。2024年5月のGoogle I/Oにて、これが「AI Overviews」として正式に米国等で展開が開始されました。
Google公式ブログ(The Keyword)でも発表されている通り、AI Overviewsは数十億の検索クエリに対して表示され始めています。
したがって、これからのWebマーケティング実務においては、「SGE対策」ではなく「AI Overviews向けのLLMO」として戦略を組む必要があります。
なぜ今LLMOが必要なのか:検索体験の変化とリスク
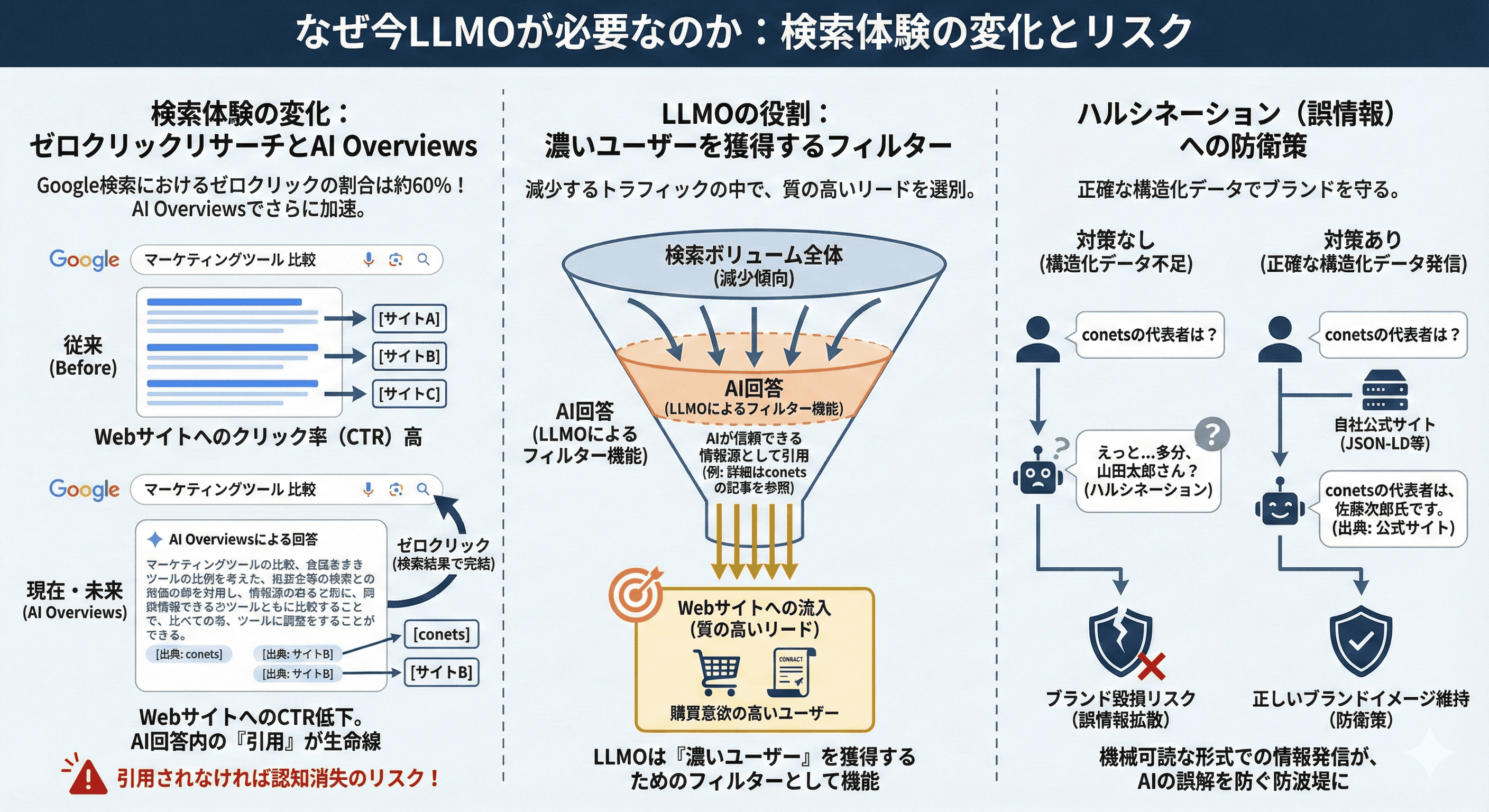
Google検索におけるゼロクリックリサーチ(検索結果画面だけで完結する行動)の割合は60%近くに達しており、AI Overviewsの導入でさらに加速します。
Webサイトへのクリック率(CTR)低下が避けられない中、LLMOを行わなければ、ユーザーの目に触れる機会そのものが消失します。AIが回答を作成する際に「信頼できる情報源」として認識されなければ、ブランドの存在自体が認知されなくなります。
ゼロクリック検索の増加と流入減の現実
ユーザー行動は劇的に変化しています。「天気」や「通貨換算」だけでなく、「マーケティングツールの比較」や「コードの書き方」といった複雑なクエリでさえ、AIが要約した回答だけで満足するユーザーが増えています。
これを「ゼロクリック検索」と呼びます。Webサイトへのトラフィック減少は避けられない事実です。
しかし、AIの回答内に「詳細はconetsの記事を参照」といった引用リンクがあれば、そこからの流入は非常に質の高い(購買意欲の高い)リードとなります。
LLMOは、減少するパイの中で「濃いユーザー」を獲得するためのフィルターとしても機能します。
ハルシネーション(誤情報の生成)への防衛策
LLMは時に、もっともらしい嘘(ハルシネーション)をつきます。
「conetsの代表者は誰ですか?」と聞いたとき、もしWeb上に正確な構造化データがなければ、AIは確率的にありそうな別の名前を回答してしまうリスクがあります。
これはブランド毀損に直結します。
自社公式サイトから正確な情報をJSON-LD等の機械可読な形式で発信することは、AIによる誤解を防ぎ、正しいブランドイメージを守るための「防衛策」でもあります。
実践的LLMO対策:AIに選ばれるための3つの柱

LLMOの具体的な対策は、Google公式ドキュメントやschema.orgの定義に基づき、「構造化データの実装」「E-E-A-Tの強化」「メンション(言及)の獲得」の3点に集約されます。
特にJSON-LDを用いた構造化データは、LLMがテキストを解析するコストを下げ、意味を正確に理解させるために不可欠です。
Google検索セントラルでも、構造化データがAIの理解を助けると言及されています。
参考:Google 検索における構造化データのマークアップの概要
1. 構造化データ(JSON-LD)による意味づけの徹底
これが最も技術的かつ即効性のある対策です。
テクニカルSEOの基礎:構造化データの役割とメリットはこちら
単にHTMLでテキストを書くだけでは、AIはその意味(これが商品名なのか、会社名なのか、価格なのか)を推測するしかありません。
schema.orgの語彙を用いて、以下のような情報を明示的に定義します。
- Organization: 会社概要、ロゴ、連絡先、SNSリンク
- Person: 著者情報、肩書き、所属
- Product: 商品スペック、価格、在庫状況
- FAQPage: よくある質問と回答
- HowTo: 手順書
これらを実装することで、AIは「推測」ではなく「確定情報」としてあなたのコンテンツをデータベースに格納します。
2. E-E-A-T(経験・専門性・権威性・信頼性)の明示
Googleの検索品質評価ガイドラインで重視されるE-E-A-Tは、AIの学習データ選定においても重要です。
AIは「信頼できるソース」を優先して引用するように調整されています。
- 著者プロフィールの充実: 誰が書いたか、その分野での実績は何か。
- 一次情報の提供: どこかのまとめ記事ではなく、自社で調査したデータや実体験に基づく見解。
- 運営者情報の透明性: 住所、電話番号、法的表記の明確化。
これらが不足しているサイトは、ノイズとしてAIの回答候補から除外される可能性が高まります。
3. デジタルPRと外部サイトでの言及(Co-occurrence)
「共起(Co-occurrence)」という概念が重要です。信頼性の高い業界メディアやニュースサイトで、「CRMならSalesforceやHubSpot」のように、ブランド名と関連キーワードがセットで言及される状況を作ります。
リンクが貼られていなくても、テキストとしての「言及(サイテーション)」があれば、LLMはエンティティ間の関係性を学習します。
プレスリリースの配信や寄稿記事などを通じて、Web全体での「指名数」を増やす活動が必要です。
Next.jsとJSON-LDを用いたLLMO実装の技術的アプローチ
Next.js(App Router)環境下では、TypeScriptの型安全性を活かしながらJSON-LDを動的に生成・注入することがLLMOに有効です。
静的なHTMLタグだけでなく、サーバーサイドでデータを取得し、schema-dts等のライブラリを用いて正確なスキーマをレンダリングします。
これにより、クローラーやLLMのエージェントがページ内容を即座にインデックスし、学習データとして取り込みやすくなります。
App Routerでの動的構造化データ生成
Next.js v13以降のApp Routerでは、layout.tsxや各page.tsxでメタデータと共にJSON-LDを注入するのがベストプラクティスです。
実践編:Next.js App Routerでのメタデータ・構造化データ実装ガイドはこちらから
推奨ライブラリであるschema-dtsを使用することで、schema.orgの仕様に準拠した型安全な記述が可能になります。
以下は、ブログ記事ページにBlogPostingの構造化データを埋め込む実装例です。
// app/blogs/[slug]/page.tsx
import { WithContext, Article, FAQPage } from 'schema-dts';
export default async function BlogPage({ params }: { params: { slug: string } }) {
// CMSなどから記事データを取得
const articleData = await getArticle(params.slug);
const jsonLd: WithContext<Article> = {
"@context": "https://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": `https://conets.jp/blogs/${params.slug}`
},
"headline": articleData.title,
"image": [articleData.thumbnailUrl],
"datePublished": articleData.publishedAt,
"dateModified": articleData.updatedAt,
"author": {
"@type": "Person",
"@id": "https://conets.jp/#ryo-sasaki"
},
"publisher": {
"@type": "Organization",
"@id": "https://conets.jp/#organization",
"name": "conets",
"logo": {
"@type": "ImageObject",
"url": "https://conets.jp/logo.png"
}
}
};
return (
<section>
{/* 構造化データをscriptタグで注入 */}
<script
type="application/ld+json"
dangerouslySetInnerHTML={{ __html: JSON.stringify(jsonLd) }}
/>
<h1>{articleData.title}</h1>
{/* 記事本文 */}
<div dangerouslySetInnerHTML={{ __html: articleData.content }} />
</section>
);
}コンテキスト情報の明確化(@idとSameAsの活用)
LLMに対して「このページで言及しているconetsは、あのconetsと同じである」と認識させるために、sameAsプロパティを活用します。
{
"@type": "Organization",
"name": "conets",
"url": "https://conets.jp",
"sameAs": [
"https://twitter.com/conets_jp", //これらはテストで実際は存在してないです
"https://www.facebook.com/conets_jp",
"https://www.linkedin.com/company/conets"
]
}また、@idを使用してエンティティに一意のID(URI)を割り振ることで、サイト内の異なるページ間でも「同じ組織」「同じ著者」であることを機械的に紐付けられます。
これらがナレッジグラフの形成を助け、LLMOの効果を最大化します。
よくある質問(FAQ)
LLMOに関する頻出の疑問に対し、専門家の視点と実務経験に基づいて回答します。
SEOとの工数配分、効果が出るまでの期間、中小企業が優先すべき施策など、現場で直面する課題を解決します。
QLLMOとSEOはどちらを優先すべきですか?
現状はSEOが主軸ですが、LLMO対策(特に構造化データ)はSEOにも好影響を与えるため、統合的に進めるのが正解です。LLMOのために作った高品質なコンテンツや構造化データは、従来の検索エンジン評価も高めます。
Q構造化データを入れるだけでAIに引用されますか?
構造化データは前提条件ですが、コンテンツ自体の品質と独自性(一次情報)がなければ引用はされません。AIは「形」だけでなく「中身」の信頼性も評価しています。
QLLMOの効果が出るまでどれくらいの期間がかかりますか?
LLMの学習サイクルやGoogleのインデックス更新頻度に依存するため、一概には言えませんが、構造化データの実装後は数週間でAI Overviewsに変化が見られるケースがあります。
一方、ChatGPT等の学習データに反映されるには数ヶ月〜年単位の時間が必要です。
Q中小企業でもLLMOに取り組む必要がありますか?
はい、むしろ中小企業こそ取り組むべきです。
大手企業と比べてドメインパワーで劣る場合でも、ニッチな専門領域における「正確な構造化データ」を提供することで、特定の質問に対するAIの回答枠を独占できるチャンスがあります。
SEO研究チャンネルの方々の分析でも、「自然検索で21位以下の圏外のURLが、AIOに表示されるURLの約38%も占めている」と指摘されています。(参考:AIが選ぶサイトの特徴とは!?【AI時代のSEO】)
Q構造化データ(JSON-LD)は必須ですか?
LLMOにおいては必須と言えます。AIが非構造化テキスト(普通の文章)を理解する能力は向上していますが、JSON-LDで明示的に意味を伝えた方が、解釈ミスを防ぎ、採用される確率は格段に上がります。
Q具体的にどのツールを使って対策すれば良いですか?
Googleのリッチリザルトテスト、Schema Markup Validator、そしてGoogle Search Consoleの構造化データレポートを活用してください。実装には前述のNext.jsや、WordPressであれば専用プラグインも有効です。
QChatGPT対策とGoogle対策は別物ですか?
基本原理は同じですが、GoogleはJSON-LDとリアルタイムのインデックス情報を重視し、ChatGPTはBingのインデックスデータや過去の学習済みデータを重視する傾向があります。
Web検索機能を持つGPT-4oなどに対しては、Google対策と同様のアプローチが有効です。
QLLMOの成功指標(KPI)は何を設定すべきですか?
「AI検索からの流入数(Search Consoleのフィルタで計測可能になりつつある)」や、「指名検索数の増加」、そして実際にAIに自社ブランドについて質問した際の「回答の正確性・引用有無」を定点観測することをおすすめします。
まとめ
LLMOは、AI検索時代における企業の生存戦略です。
検索順位を追うだけのSEOから脱却し、構造化データと高品質な一次情報によって、AIに「信頼される情報源」として認識させる必要があります。
GoogleのAI Overviews導入やLLMの進化は不可逆な流れであり、早期にLLMOに取り組むことで、競合他社に先駆けてAI回答内でのポジション(引用枠)を確保できます。
無料相談の案内
この記事で解説したLLMOの概念は共通ですが、最適な実装方法は貴社の技術スタック(Next.jsかWordPressか等)やビジネスモデルによって異なります。
- 「自社のサイトがAIにどう認識されているか知りたい」
- 「構造化データを実装したいが、エンジニアのリソースが足りない」
- 「SEOとLLMOの予算配分を相談したい」
このような課題をお持ちであれば、まずは現状を整理するところから始めませんか?
conetsの無料相談で得られる価値
- 自社のLLMO/SEO対応状況をプロ視点で5分診断
- AI Overviews時代に優先すべき施策の順位付け
- 技術的な実装(JSON-LD/Next.js)の具体的なアドバイス
- 無駄な広告費やツール費用を削減するための見直し
- 競合とのデジタルプレゼンスのギャップを可視化
この記事の改善内容は企業ごとに最適解が異なります。
まずは5分で状況を確認できる無料相談をご用意しています。


